Lentelės formatas
DSA yra sudarytas taip, kad būtų patogu dirbti tiek žmonėms, tiek programoms. Žmonės su DSA lentele gali dirbti naudojantis, bet kuria skaičiuoklės programa ar kitas pasirinktas priemones. Kadangi DSA turi aiškią ir griežtą struktūrą, lentelėje pateiktus duomenis taip pat gali lengvai nuskaityti ir interpretuoti kompiuterinės programos.
Tais atvejais, kai su DSA lentele dirba žmonės, lentelė gali būti saugoma įstaigos pasirinktos skaičiuoklės programos ar kitų priemonių formatu.
Automatizuotoms priemonėms DSA turi būti teikiamas CSV formatu laikantis RFC 4180 taisyklių, failo koduotė turi būti UTF-8.
Lentelės struktūra
Rengiant duomenų struktūros aprašus darbas vyksta su viena lentele. Lentelė
sudaryta iš 15 stulpelių. Iš 15 stulpelių, pirmasis stulpelis id yra
eilutės identifikatorius, kuris pildomas automatiškai, toliau seka 5
dimensijų stulpeliai ir likę 9 stulpeliai yra metaduomenys
apie duomenis.
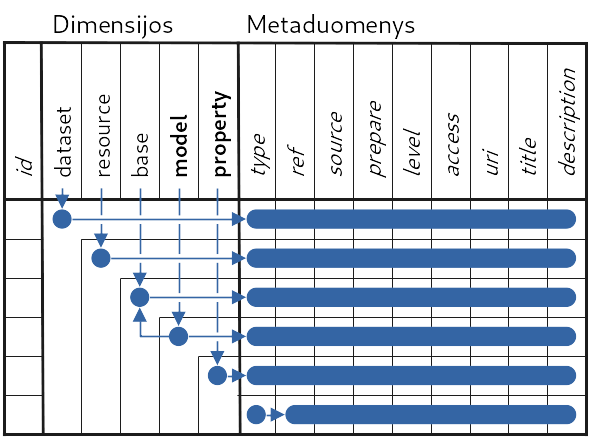
Lentelė sudaryta hierarchiniu principu. Kiekvienas metaduomenų stulpelis gali
turėti skirtingą prasmę, priklausomai nuo dimensijos. Todėl toliau
dokumentacijoje konkrečios dimensijos stulpelis yra žymimas nurodant tiek
dimensijos, tiek metaduomenis pavadinimus, pavyzdžiui model.ref,
kuris nurodo ref stulpelį, esantį model dimensijoje.
Ką reiškia kiekvienas stulpelis paaiškinta žemiau.
- id
Eilutės identifikatorius
Unikalus elemento numeris, gali būti sveikas, monotoniškai didėjantis skaičius arba UUID. Svarbu užtikrinti, kad visi elementai turėtu unikalų id.
Šis stulpelis pildomas automatinėmis priemonėmis, siekiant identifikuoti konkrečias metaduomenų eilutes, kad būtų galima atpažinti metaduomenis, kurie jau buvo pateikti ir po to atnaujinti.
Šio stulpelio pildyti nereikia.
Dimensijos
Duomenų struktūros aprašo lentelė sudaryta hierarchiniu principu. Kiekvienos lentelės eilutės prasmę apibrėžia viena iš penkių dimensijų. Kiekvienoje eilutėje gali būti užpildytas tik vienas dimensijos stulpelis.
Be šių penkių dimensijų, yra kelios papildomos dimensijos, jos nurodomos type stulpelyje, neužpildžius
nei vieno dimensijos stulpelio.
- dataset
Duomenų rinkinys
Kodinis duomenų rinkinio pavadinimas. Atitinka dcat:Dataset prasmę. Žiūrėti Duomenų rinkinys.
- resource
Duomenų šaltinis
Kodinis duomenų šaltinio pavadinimas. Atitinka dcat:Distribution prasmę. Žiūrėti Duomenų šaltinis.
- base
Modelio bazė
Kodinis bazinio modelio pavadinimas. Atitinka rdfs:subClassOf prasmę (
modelrdfs:subClassOfbase). Žiūrėti Modelio bazė.
- model
Modelis (lentelė)
Kodinis modelio pavadinimas. Atitinka rdfs:Class prasmę. Žiūrėti Duomenų modelis.
- property
Savybė (stulpelis)
Kodinis savybės pavadinimas. Atitinka rdfs:Property prasmę. Žiūrėti Savybė.
Metaduomenys
Kaip ir minėta aukščiau, kiekvienos metaduomenų eilutės prasmė priklauso nuo
Dimensijos. Todėl, toliau dokumentacijoje, kalbant apie tam tikros
dimensijos stulpelį, stulpelis bus įvardinamas pridedant dimensijos
pavadinimą, pavyzdžiui model.ref, kas reikštų, kad kalbama apie
ref stulpelį, model dimensijoje.
- type
Tipas
Prasmė priklauso nuo dimensijos. Žiūrėti Duomenų tipai.
Jei nenurodytas nei vienas dimensijos stulpelis, tuomet šiame stulpelyje nurodoma papildoma dimensija.
- ref
Ryšys
Prasmė priklauso nuo dimensijos. Žiūrėti Ryšiai tarp modelių, Matavimo vienetai ir Klasifikatoriai.
- source
Šaltinis
Duomenų šaltinio struktūros elementai. Žiūrėti Duomenų šaltiniai.
- prepare
Formulė
Formulė skirta duomenų atrankai, nuasmeninimui, transformavimui, tikrinimui ir pan. Žiūrėti Formulės.
- level
Brandos lygis
Duomenų brandos lygis, atitinka 5 Star Data. Žiūrėti Brandos lygiai.
- access
Prieiga
Duomenų prieigos lygis. Žiūrėti Prieigos lygiai.
- uri
Žodyno atitikmuo
Sąsaja su išoriniu žodynu. Žiūrėti Išoriniai žodynai.
- title
Pavadinimas
Elemento pavadinimas.
Visi stulpeliai lentelėje yra neprivalomi. Stulpelių tvarka taip pat nėra
svarbi. Pavyzdžiui jei reikia apsirašyti tik globalių modelių struktūrą,
nebūtina įtraukti dataset, resource ir base stulpelių.
Jei norima apsirašyti tik prefiksus naudojamus uri lauke, užtenka
turėti tik prefiksų aprašymui reikalingus stulpelius.
Įrankiai skaitantys DSA, stulpelius, kurių nėra lentelėje turi interpretuoti kaip tuščius. Taip pat įrankiai neturėtų tikėtis, kad stulpeliai bus išdėstyti būtent tokia tvarka. Nors įrankių atžvilgiu stulpelių tvarka nėra svarbi, tačiau rekomenduotina išlaikyti vienodą stulpelių tvarką, tam kad lenteles būtų lengviau skaityti.
Vardų erdvės
dataset ir model esantys pavadinimai turi būti globaliai
(Lietuvos mastu) unikalūs. Kad užtikrinti pavadinimų unikalumą dataset
ir model pavadinimai formuojami pasitelkiant vardų erdves.
- /<standard>/
Standartų vardų erdvė
Standartų vardų erdvė formuojama egzistuojančių standartų ir išorinių žodynų pagrindu suteikiant vardų erdvei
<standard>standarto sutrumpintą pavadinimą. Pavyzdžiui atvirų duomenų katalogo metaduomenys turėtų keliauti į/dcat/vardų erdvę. Standartų sutrumpintus pavadinimus rekomenduojame imti iš Linked Open Vocabularies katalogo.
- /datasets/<type>/<org>/
Įstaigų vardų erdvė
Konkrečios organizacijos vietinė rinkinio vardų erdvė. Rekomenduojama
<org>reikšmei naudoti organizacijos trumpinį, kad bendras modelio pavadinimas nebūtų per daug ilgas.Galimos
<type>reikšmės:- gov
Valstybinės įstaigos.
- com
Verslo įmonės.
- /datasets/<type>/<org>/<dataset>/
Įstaigų duomenų rinkinių vardų erdvė
Įstaigos duomenų rinkinio vardų erdvė į kurią patenka visi įstaigos duomenų modeliai.
Viskas, kas eina po
/datasets/<type>/<org>/yra įstaigos vardu erdvė, kurioje įstaiga, gali įsitraukti papildomas vardų erdves, pavyzdžiui/datasets/<type>/<org>/<isr>/<dataset>, kuri<isr>yra Informacinės sistemos ar Registro trumpinys.
- /provisional/
Duomenų rinkiniai turintys negalutinę struktūrą
Šioje vardų erdvėje talpinamos visos kitos vardų erdvės, kurių duomenų struktūra nėra galutinė ir gali keistis, be atskiro įspėjimo.
Visos duomenų rinkinius rekomenduojame pirmiausiai kelti į šią duomenų erdvė ir įsitikimus, kad duomenų struktūra yra stabili, perkelti į kitą atitinkamą vardų erdvė.
Naujai atveriami duomenų struktūros aprašai sudaromi ŠDSA
pagrindu. Įprastai duomenų bazių struktūra nėra kuriama vadovaujantis
standartais. Vidinės struktūros dažniausiai kuriamos vadovaujantis sistemai
keliamais reikalavimais. Todėl naujai atveriamų duomenų rinkiniai turi keliauti
į duomenų rinkinio vardų erdvę /datasets/<type>/<org>/<dataset>/, išlaikant
pirminę duomenų struktūrą ir neprarandant duomenų.
Tačiau su laiku, dalis įstaigos duomenų iš duomenų rinkinio vardų erdvės turėtu būti perkeliami į globalią duomenų erdvę. Į globalią duomenų erdvę pirmiausiai turėtų būti perkeliami tie duomenys, kurie yra plačiai naudojami. Perkėlimas į globalią duomenų erdvę nepanaikina duomenų rinkinio iš ankstesnės vardų erdvės, tiesiog duomenų rinkinio duomenų pagrindu kuriama kopija į globalią duomenų erdvę.
Reliatyvūs pavadinimai
Modelio pavadinimas gali būti absoliutus arba reliatyvus. Absoliutūs
pavadinimai prasideda / simboliu, reliatyvus pavadinimai prasideda be /
simbolio ir yra jungiami su vardų erdvės pavadinimu, kurios kontekste yra
apibrėžtas modelis.
Pavyzdžiui, turinti tokį duomenų struktūros aprašą:
id |
d |
r |
b |
m |
property |
type |
|---|---|---|---|---|---|---|
1 |
dcat |
ns |
||||
2 |
dataset |
|||||
3 |
title |
|||||
4 |
datasets/gov/ivpk/adk |
|||||
5 |
adk |
|||||
6 |
/dcat/dataset |
alias |
||||
7 |
dataset |
|||||
8 |
title |
|||||
Matome, kad yra apibrėžti du modeliai:
dcat/datasetdatasets/gov/ivpk/adk/dataset
Vienas dataset modelis yra apibrėžtas dcat vardų erdvės kontekste, kitas
datasets/gov/ivpk/adk vardų erdvės kontekste.
Kai modelio pavadinimas yra naudojamas vardų erdvės kontekste ir pavadinimas
neprasideda / simboliu, tada tai yra reliatyvus modelio pavadinimas.
Reliatyvus modelio pavadinimas yra jungiamas su vardų erdvės pavadinimu,
kurios kontekste yra apibrėžtas modelis.
Jei tam tikros vardų erdvės kontekste norime įvardinti modelį, kuris yra už
tos vardų erdvės konteksto ribų, būtina naudoti absoliutų modelio pavadinimą,
kuris prasideda / simboliu. Taip yra padaryta 6-oje eilutėje, kur nurodyta,
kad datasets/gov/ivpk/adk/dataset bazė yra dcat/dataset modelis iš kitos
vardų erdvės.
Visais atvejais, kai modelio pavadinimas naudojamas nenurodant jokio vardų
erdvės konteksto, / simbolio pavadinimo pradžioje naudoti nereikia.
Pavyzdžiui šiame tekste įvardinti dcat/dataset ir
datasets/gov/ivpk/adk/dataset modelių pavadinimai neprasideda / simboliu.